Go 1.25's Experimental Green Tea GC Optimizes Memory
·5 min read
Go's garbage collector has always been a hot topic, often a source of both admiration for its simplicity and frustration over its performance quirks. Now, with the impending Go 1.25 release, we're seeing a significant shift: a new, experimental garbage collector dubbed "Green Tea." It's available right now for testing, and the initial numbers suggest it could be a big deal for some workloads.
Green Tea's Early Promise
So, what's the headline? Many Go applications could see a roughly **10% decrease in time spent on garbage collection**. That's a solid improvement. But for certain specific workloads, the gains are far more dramatic, with reported reductions climbing as high as **40%**. That kind of jump isn't just incremental; it hints at a fundamental re-architecture.
To kick the tires on Green Tea, you'll need to enable it at build time by setting `GOEXPERIMENT=greenteagc`. While it's labeled "experimental," it's already considered production-ready, actively running inside Google's own infrastructure. This isn't some academic exercise; it's a tested system. The Go team, authors Michael Knyszek and Austin Clements note that while many will benefit, not *every* workload will see significant improvement, or any at all. That's why community feedback is critical; they're actively encouraging developers to try it out. Based on current data, the plan is to make Green Tea the default GC in Go 1.26.
If you hit a snag or discover an actual bug, the team asks you to file a new issue. For positive feedback or confirmation of improved performance, you can chime in on the existing Green Tea issue. This blog post itself is derived from Michael Knyszek’s GopherCon 2025 talk, which you can watch here:
Demystifying Go's Garbage Collection
Before we dive into *why* Green Tea is needed, it's worth a quick refresher on how Go handles memory. The core job of any garbage collector is straightforward: automatically identifying and reclaiming memory that your program no longer needs. In Go, this boils down to tracking *objects* and *pointers*.
Think of *objects* as chunks of memory allocated on the heap—essentially, Go values that the compiler can't reliably place on the stack because their lifetime is uncertain. For instance, a global slice's backing store, like `var x = make([]*int, 10)`, typically lands on the heap. *Pointers*, then, are simply memory addresses that let your program refer to these objects. They're the glue that connects different parts of your program to allocated data.
Go's garbage collector employs a strategy known as *tracing garbage collection*. This means it literally "traces" through your program's pointers to figure out which objects are still actively being used. The specific algorithm Go implements is called **mark-sweep**.
How Mark-Sweep Works (Simply)
Imagine your program's memory as a vast graph, where each *object* is a node, and every *pointer* forms an edge. The mark-sweep algorithm navigates this graph in two distinct phases:
1. **The Mark Phase:** The GC starts from well-defined "roots" – things like global variables or active local variables on the stack. From these roots, it systematically traverses the entire graph, following every pointer it finds. As it encounters an object, it "marks" it as visited. This is akin to a flood-fill algorithm, like a depth-first or breadth-first search, ensuring it doesn't get stuck in loops. The runtime uses a simple "seen bit" in the object's metadata to keep track of this.
2. **The Sweep Phase:** Once the marking is complete, any object that *wasn't* marked as visited is, by definition, "unreachable" by your program. You can't access it anymore. In this phase, the GC iterates through all unmarked objects and flags their memory as free, making it available for subsequent allocations.
It might sound simple, and at its core, it really is a graph traversal. However, the practical implementation has layers of complexity. For example, this entire process runs concurrently with your regular Go code, which introduces challenges when the graph is constantly changing. It's also parallelized to speed things up, a detail that becomes important when understanding the problems Green Tea addresses.
*(The original article included a detailed slideshow example of the graph flood. As a journalist, I'd describe its essence rather than reproduce it frame-by-frame, and assume my reader can visualize or refer to the original if needed.)*
Here's the thing: while the underlying logic is straightforward, the performance implications are anything but.
The Problem: A Microarchitectural Disaster
For years, Go's GC has been "good enough," but "good enough" often comes with hidden costs. The reality is that many Go programs spend a significant chunk of their CPU time—often **20% or more**—just on garbage collection. That's a substantial overhead that directly impacts application performance and resource consumption.
When you break down the garbage collector's cost, it boils down to two main factors: how frequently it runs, and how much work it does each time. The Go team has addressed the "how often" part extensively in the past (like Michael Knyszek's GopherCon EU 2022 talk on memory limits or the official Go GC guide). But Green Tea focuses squarely on the "average cost per GC cycle."
Years of profiling CPU usage have revealed two critical insights into Go's existing GC:
First, the vast majority of the work, roughly **90%**, occurs during the *mark phase*. The sweep phase, by contrast, is lean and efficient, accounting for only about 10% of the cost. This means any major performance gains have to come from improving the marking process.
Second—and this is where things get gnarly—a significant portion of that marking time, at least **35%**, isn't even spent doing useful work. It's spent *stalled*, waiting to access heap memory. This isn't just an inefficiency; it actively sabotages how modern CPUs achieve speed. The original post doesn't pull any punches, calling this a "**microarchitectural disaster**."
What does that mean, exactly? It suggests that the existing GC's memory access patterns are fundamentally at odds with the design of contemporary processors, causing bottlenecks that prevent the CPU from running at its full potential. This "stalling" isn't just about wasted cycles; it's about disrupting the very pipeline mechanisms that make modern hardware fast.
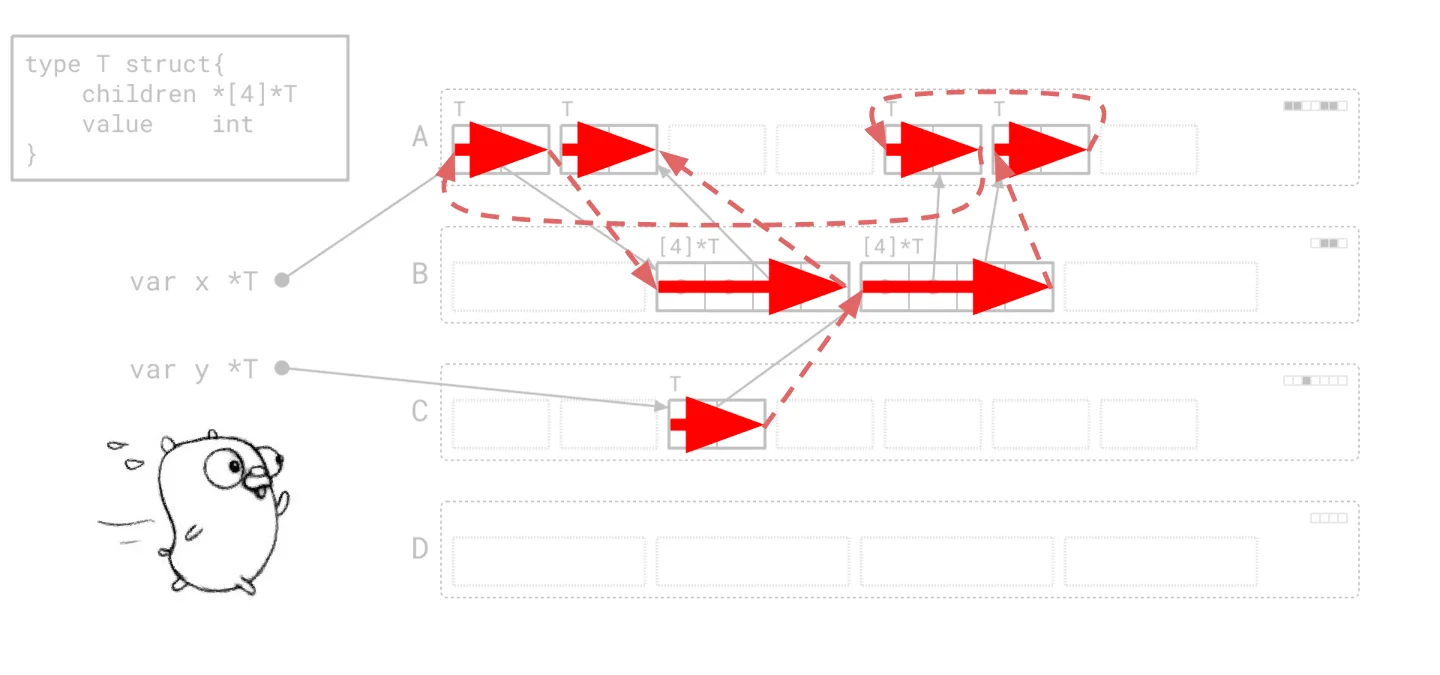
This is the deep-seated problem Green Tea aims to solve. The question, then, is how this new collector manages to untangle such a complex, hardware-level performance drain. That's what we'll explore next.Here's the thing: modern garbage collection, particularly the classic mark-sweep approach like Go's, has a fundamental mismatch with how today's CPUs actually work. Forget the idealized vision of a super-fast engine; the existing "graph flood" algorithm is like trying to drive a Formula 1 car through dense city traffic. The CPU can't see past the next intersection, forcing it to constantly brake, turn, and start again. You're never really *going* anywhere fast.
The original graph flood GC algorithm makes tiny, erratic jumps across the heap, hindering efficiency.
What does that mean in practice? The garbage collector ends up jumping wildly across memory. It might pick at a few bytes here, then leap to a completely different page to scan another object, only to jump back again. This isn't just inefficient; it's actively hostile to CPU caches. Your main memory can be a hundred times slower than what's in cache, but caches rely on spatial and temporal locality – accessing data that's nearby or just used. The graph flood's erratic behavior means the CPU is almost always fetching from slow main memory. It's not just the fetches themselves, either; because each piece of work is small and unpredictable, the CPU is forced to stall, waiting for each memory request to complete before it can proceed. There's no opportunity to overlap slow operations.
And the problem is only getting worse. We used to rely on the industry adage: "wait two years and your code will get faster." For Go's mark-sweep GC, the opposite feels true: "wait two years and your code will get slower." Contemporary CPU architectures introduce several new challenges that actively undermine traditional garbage collection performance. We're seeing **Non-Uniform Memory Access (NUMA)**, where memory access speeds depend on which CPU core is doing the accessing. One core's local memory is faster than another's, complicating parallel processing. You can see how this plays out in core-to-core latency benchmarks, which illustrate just how variable memory access costs have become depending on the specific CPU core involved.
Then there's the **reduced memory bandwidth per core**. While we're packing more cores onto chips, the total memory bandwidth hasn't kept pace. Each core can submit fewer main memory requests relative to its processing power, meaning more stalls for non-cached data. Even with **more CPU cores** overall, the gains are limited. Parallelizing the graph flood eventually hits a bottleneck with its shared work queue, regardless of how carefully it's designed. Finally, modern **vector instructions** on hardware offer massive speedups by processing large data sets at once, but the graph flood's irregular, varied-size objects and metadata (ranging from a couple of bits to thousands) offer no opportunity to exploit this parallelism. The unpredictability simply shuts down this path to performance.
## Green Tea: A Smarter Approach to Marking
This brings us to Green Tea, a novel take on the mark-sweep algorithm designed to overcome these challenges. Its core concept is almost deceptively simple: *work with pages, not objects*.
It sounds trivial, doesn't it? But implementing this effectively required a significant engineering effort to re-think how the object graph is traversed and what metadata needs tracking. Concretely, Green Tea shifts the paradigm: we now scan entire memory pages instead of individual objects, and our work lists track pages, not objects. While we still need to mark individual objects, that marking is now managed locally within each page.
To really grasp the difference, consider the visual example. In a detailed walkthrough (like the slideshow provided in the full article), you'd observe how Green Tea navigates the heap. It uses two bits of metadata per object – "seen" and "scanned" – which are critical because the work list now manages pages. As the algorithm follows pointers from roots, it adds entire pages to a work list. Crucially, Green Tea employs a first-in-first-out (FIFO), or queue-like, order for these pages. This is a deliberate departure from the traditional last-in-first-out (LIFO) approach, allowing objects to accumulate on a page while it waits in the queue. When a page is finally processed, all its "seen" but "unscanned" objects can be handled in a contiguous burst. This "lazy" approach isn't a shortcut; it’s a virtue, enabling the algorithm to perform many small bits of work on a page all at once, in memory order.
## Getting on the Highway
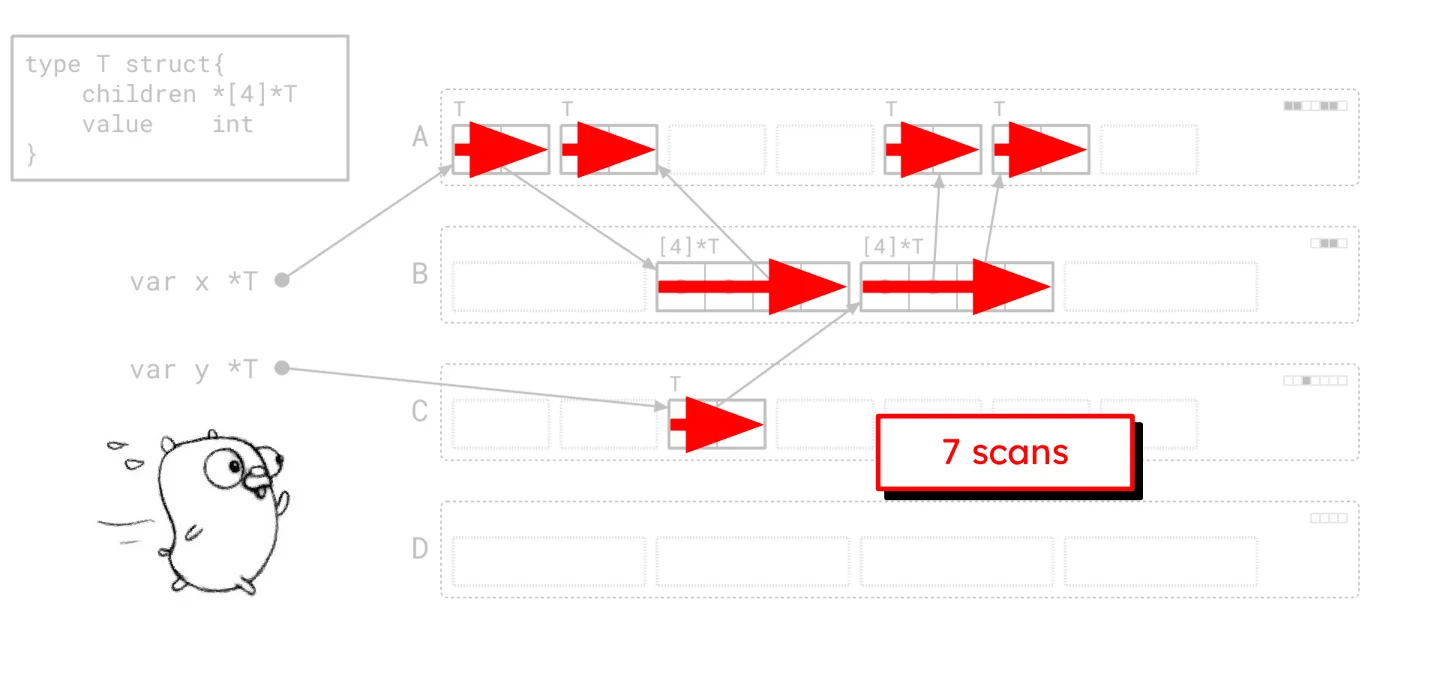
Remember that frustrating city traffic analogy for the old graph flood?
The original graph flood makes numerous, disjointed scans.
It jumped everywhere, requiring seven distinct scans in our example. Green Tea paints a very different picture:
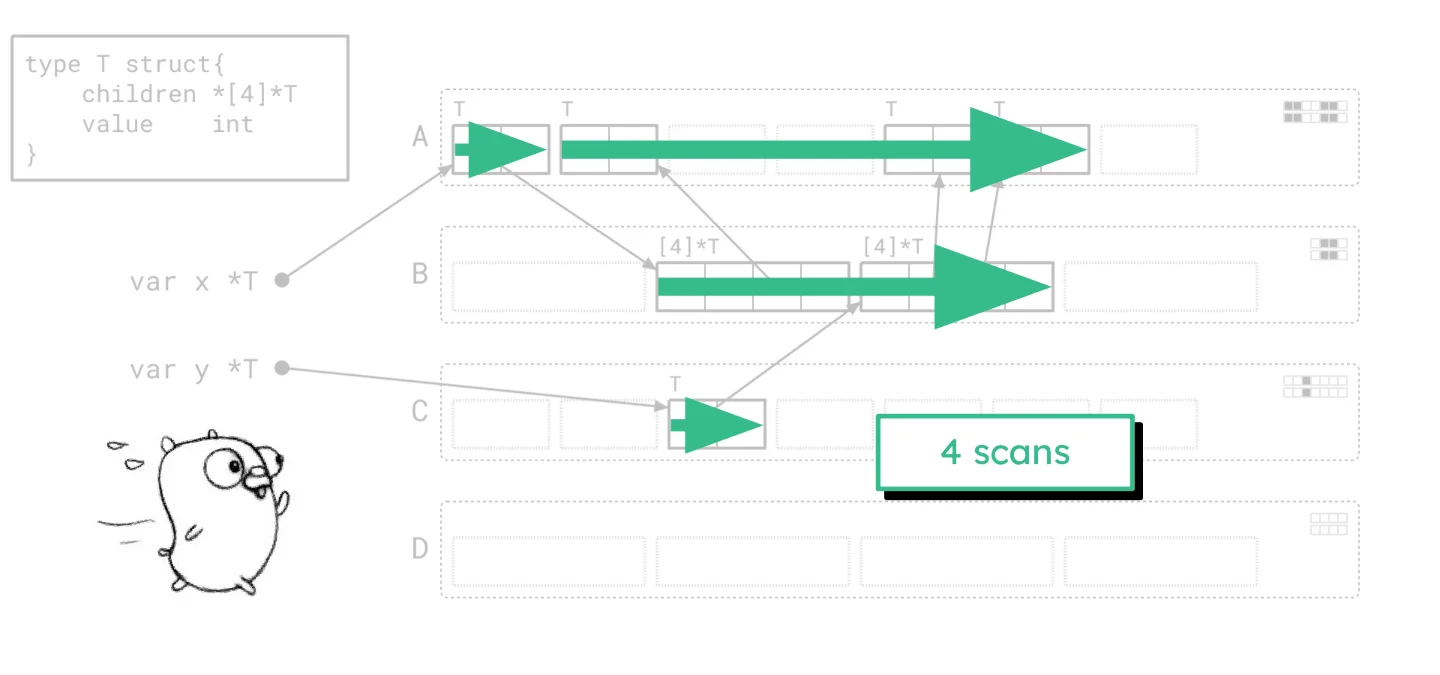
Green Tea streamlines the process, resulting in fewer, longer scans.
Green Tea takes fewer, longer, sequential passes across memory pages – just four scans in the same example. This is where the magic happens. Longer, more contiguous memory access fundamentally changes the game. It’s a far better fit for modern microarchitectures, drastically increasing the probability that objects are scanned from cache rather than slow main memory. Per-page metadata also becomes more cache-friendly. Smaller work lists, tracking pages instead of individual objects, reduce contention and CPU stalls. This isn't just an optimization; it's a structural realignment.
And speaking of a highway, Green Tea also allows us to finally shift into gears previously unavailable: vector hardware.
## Turbo-charging with Vector Acceleration
For anyone only vaguely familiar with vector hardware, its application here might seem a stretch. Yet, Green Tea's page-centric design makes it highly amenable to specific capabilities in modern vector units: particularly wide registers and advanced bit-wise operations.
Consider AVX-512, widely supported on modern x86 CPUs. These registers are 512-bit wide – ample space to hold *all* the metadata for an entire page in just two registers, right on the CPU. This enables Green Tea to process a full page using only a handful of straightforward instructions. While basic bit-wise operations have been around for a while, newer hardware like AMD Zen 4 and Intel Ice Lake chips introduce powerful new bit vector instructions. These "Swiss army knife" operations allow a crucial step in Green Tea's scanning process to execute in just a few CPU cycles. Combined, these features dramatically accelerate the core scanning loop of Green Tea.
This kind of vectorization was a non-starter for the traditional graph flood. Its object-by-object approach meant constantly dealing with objects of wildly varying sizes and metadata requirements – from two bits to ten thousand. The lack of predictability and regularity made vector hardware utterly impractical.
A high-level view of the AVX-512 vector kernel for Green Tea scanning.
At a high level, the AVX-512 scanning kernel works like this: First, it fetches the "seen" and "scanned" bits for a page, where each bit corresponds to an object of uniform size within that page. Then, these two bit sets are compared. Their union forms the new "scanned" bits, while their difference yields an "active objects" bitmap, indicating which objects need processing in the current pass. This "active objects" bitmap is then "expanded." If, for instance, a page contains objects that are 6 words (48 bytes) long, each bit in the active objects bitmap is copied to 6 bits in an "active words" bitmap. So, `0 0 1 1 ...` would become `000000 000000 111111 111111 ...`.
0 0 1 1 ...
→
000000 000000 111111 111111 ...
Next, the kernel retrieves the pointer/scalar bitmap for the page, which is managed by the memory allocator and indicates whether each 8-byte word stores a pointer. By intersecting this pointer/scalar bitmap with the "active words" bitmap, we generate an "active pointer bitmap." This bitmap precisely pinpoints every pointer within any live, as-yet-unscanned object on that page. Finally, the system iterates over the page's memory, leveraging vector instructions to process 64 bytes at a time. It loads pointer values at locations indicated by the active pointer bitmap and writes them to a buffer, ready to mark other objects as seen and add their respective pages to the work list. It's a highly optimized, streamlined process – a direct result of Green Tea's page-centric design.Okay, let's unpack how Green Tea actually delivers on its promise of faster garbage collection. This isn't just a clever algorithm; it's a deep dive into hardware-specific optimizations and a testament to sustained collaborative engineering.
## The Secret Sauce: Hardware-Assisted Bit Twiddling
The core of Green Tea's speed comes down to some seriously specialized instruction sets, specifically the `VGF2P8AFFINEQB` instruction. This isn't just any instruction; it's a key player in the "Galois Field New Instructions" x86 extension, effectively a bit manipulation "Swiss army knife" that powers a crucial step in the scanning kernel.
What makes it so efficient? This instruction performs bit-wise affine transformations. Imagine treating each individual byte within a vector as its own 8-bit mathematical vector. `VGF2P8AFFINEQB` then multiplies that byte by an 8x8 bit matrix, all operating over the Galois field `GF(2)`. For us mere mortals, that simply means bitwise AND for multiplication and XOR for addition. The genius here is that this allows Go's runtime to define specific 8x8 bit matrices for each object size, performing the exact 1:n bit expansion needed with incredible speed. It’s a niche, highly optimized operation, and it’s clearly making a difference.
For those keen on the nitty-gritty, the full assembly code lives in [this file](https://cs.opensource.google/go/go/+/master:src/internal/runtime/gc/scan/scan_amd64.s;l=23;drc=041f564b3e6fa3f4af13a01b94db14c1ee8a42e0). Interestingly, the "expanders"—which handle these varying matrices and permutations for different size classes—are generated by [separate Go code](https://cs.opensource.google/go/go/+/master:src/internal/runtime/gc/scan/mkasm.go;drc=041f564b3e6fa3f4af13a01b94db14c1ee8a42e0) and stored in [another assembly file](https://cs.opensource.google/go/go/+/master:src/internal/runtime/gc/scan/expand_amd64.s;drc=041f564b3e6fa3f4af13a01b94db14c1ee8a42e0). It's a surprisingly compact codebase, largely because operations are kept purely within registers. There's even talk of [eventually replacing this assembly with Go code](https://go.dev/issue/73787), which would be a significant development for maintainability. Credit for devising this clever process goes to Austin Clements; it truly is both cool and fast.
## What Does It Actually Buy You?
So, beyond the technical elegance, does Green Tea deliver real-world gains? The numbers suggest a solid "yes."
Even without the upcoming vector enhancements, benchmark suites show garbage collection CPU costs dropping by 10% to 40%. To put that into perspective, if your application typically dedicates 10% of its CPU time to GC, you could see an overall CPU reduction of 1% to 4%, depending on the workload's specifics. A 10% reduction in GC CPU time appears to be the most common outcome, and you can dig into some of these specifics on the [GitHub issue](https://go.dev/issue/73581). What's more, Google has already deployed Green Tea internally, observing consistent results at scale.
The good news doesn't stop there. Those vector enhancements, still rolling out, are projected to cut GC CPU time by an *additional* 10%. That's a compounding improvement that could seriously shift the performance profile for many Go applications.
However, it's not a silver bullet. While most workloads will benefit, some won't see much, if any, improvement. Green Tea operates on the idea that you can collect enough objects on a single memory page in one pass to justify the overhead of this accumulation process. This works beautifully when your heap has a consistent structure—objects of similar sizes, at similar depths in the object graph. But for workloads that might only have one object to scan per page, the accumulation effort can actually make things worse than the traditional "graph flood" approach. The Green Tea implementation does include a special case for these single-object pages to mitigate regressions, but it can't eliminate them entirely.
Here's an interesting finding: you don't need a huge accumulation to win. The team found that scanning just 2% of a page at a time can already outperform the older graph flood method. That’s a surprising degree of efficiency, suggesting Green Tea’s design is more forgiving than one might initially expect.
## Availability and the Road Ahead
Green Tea isn't just theoretical; it's already available as an experimental feature in the recent Go 1.25 release. You can enable it by setting the environment variable `GOEXPERIMENT` to `greenteagc` during your build. Just remember, this current experimental version doesn't include the vector acceleration discussed earlier.
The plan is to make Green Tea the *default* garbage collector in Go 1.26. If you prefer the old ways, you'll still have the option to opt out using `GOEXPERIMENT=nogreenteagc` at build time. Go 1.26 will also introduce vector acceleration for newer x86 hardware, alongside a host of other tweaks and improvements based on early feedback.
If you're working with Go, I'd strongly encourage you to try it out with the Go tip-of-tree. Even if you're sticking with Go 1.25, your feedback is valuable. Head over to [this GitHub comment](https://github.com/golang/go/issues/73581#issuecomment-2847696497) for details on what diagnostics the team is looking for and the best channels for reporting your experiences.
## The Journey: Not a Solitary Spark
It’s easy to look at a clever piece of technology like Green Tea and imagine it sprang from a single moment of genius. But that narrative rarely holds up in the real world, and it certainly doesn't here. Green Tea is a prime example of the messy, collaborative, and often protracted journey of significant software development.
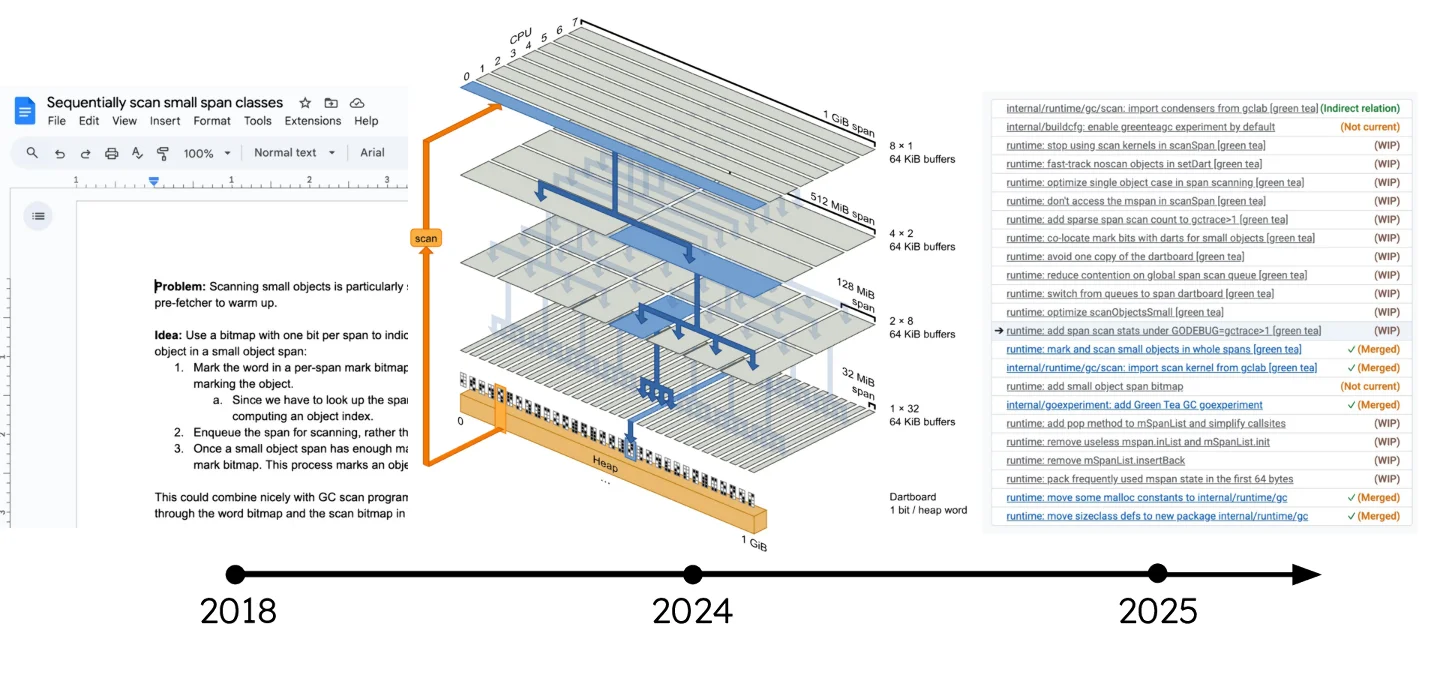
A timeline depicting a subset of the ideas we tried in this vein before getting to
where we are today.
The initial seeds for this concept were planted all the way back in 2018. It’s funny, the team itself isn’t even sure who had the very first idea; everyone attributes it to someone else. It took years of work from numerous individuals on the Go team, including Michael Pratt, Cherry Mui, David Chase, and Keith Randall, to refine the ideas. Crucial microarchitectural insights came from Yves Vandriessche, then at Intel, which helped guide the design. There were plenty of dead ends and countless details to iron out before this seemingly "simple" idea became viable.
The name "Green Tea" itself has a story, emerging in 2024 when Austin Clements prototyped an earlier version while café crawling in Japan—drinking, naturally, a lot of matcha. That prototype proved the core concept, and from there, the momentum built. Through 2025, Michael Pratt took on the implementation and productionization, further evolving the design.
This wasn't a project that any single person could have tackled alone. Green Tea isn't just an algorithm; it's an entire design space. The real work isn't just having the initial spark, but painstakingly figuring out the specifics and proving the concept. Now that the hard work is done, the team is finally in a position to iterate and refine it.
The future for Green Tea looks promising. If you're building with Go, trying it out and sharing your feedback is the best way to contribute to its continued evolution. The team is genuinely excited about this work and eager to hear from the community.