The Hard Truth About AI in Analytics: It Won't Fix Your Data Mess
For years, businesses have grappled with a frustrating paradox: an abundance of data trapped behind technical gatekeepers. Marketing teams, product managers, and sales reps often need quick answers to drive decisions, but the path from a simple question to an actionable insight usually involves navigating complex databases, understanding obscure metric definitions, or, most commonly, waiting for an analyst. This isn't a problem of missing data; it's a problem of accessibility.
The promise of large language models (LLMs) and natural language interfaces has seemed like the silver bullet. Imagine simply asking your database a question in plain English and getting an immediate, accurate answer. Many companies are rushing to connect LLMs directly to their data warehouses, hoping to democratize data access overnight. But as OLX, a prominent classifieds platform, discovered through its "Talk2Data" project, this instinct often misses a critical point: AI doesn't fix inherent data problems, it amplifies them. The real solution isn't just about advanced AI; it's about rigorous data governance and a carefully constructed semantic layer.

Talk2Data: A Blueprint for Controlled Analytics Self-Service
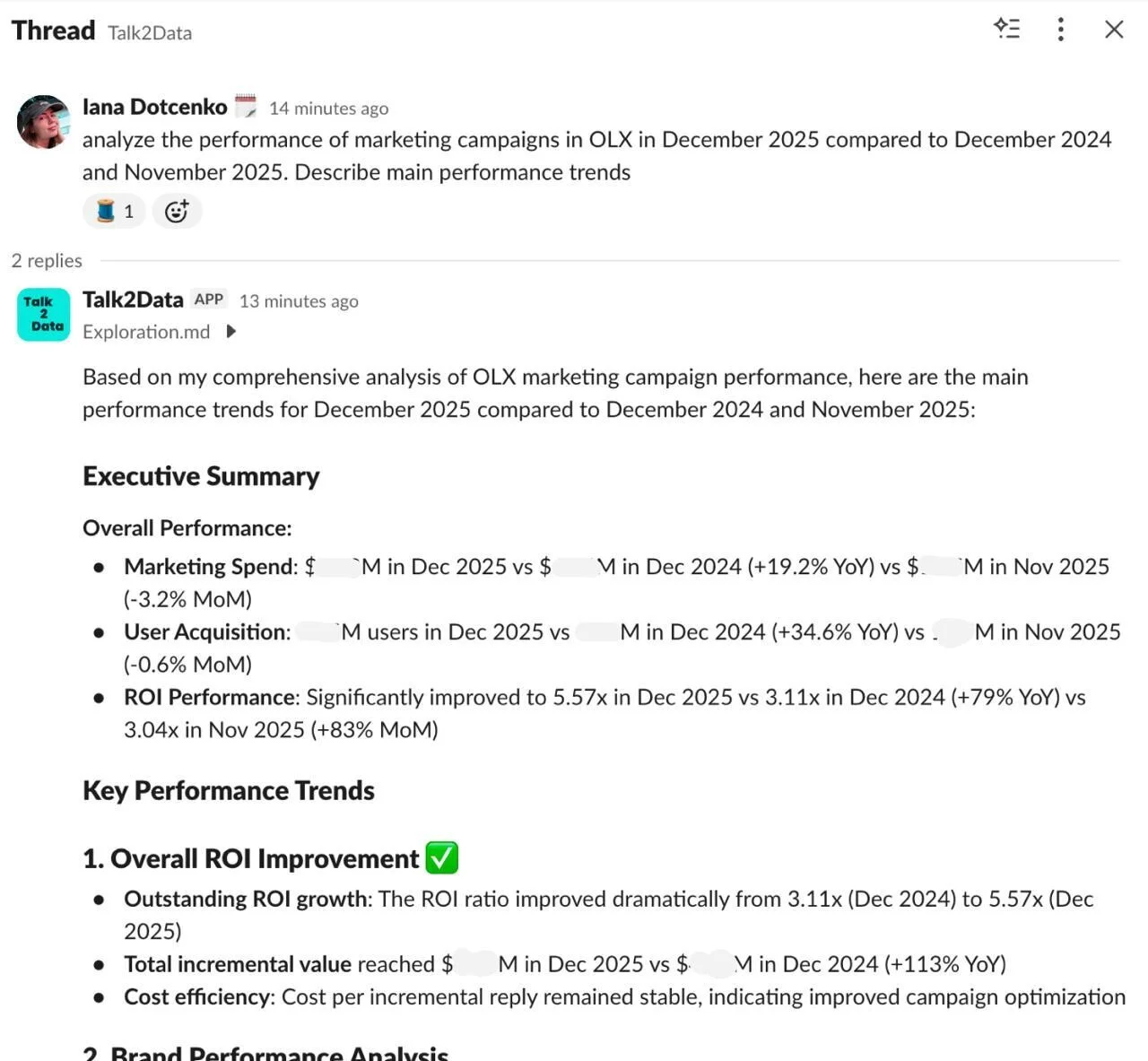
At OLX, where multi-million dollar marketing budgets are common and dozens of stakeholders need swift analytical insights, the bottleneck was clear. Analysts were swamped with repetitive ad-hoc requests, and business teams faced delays. Their answer wasn't a free-form chatbot, but Talk2Data, an internal AI agent integrated into Slack. This agent translates natural language questions into SQL queries and then returns natural language answers directly to the user.
The core distinction here is vital: OLX didn't build a generic LLM interface connected to its entire database schema. Instead, they engineered Talk2Data as a controlled analytics interface. It operates within a tightly defined model, supporting only pre-approved metrics and dimensions. This intentional constraint is fundamental. If you're building production systems that demand precision, low error rates, and zero hallucinations, bounded behavior isn't a limitation; it's a feature. The system's flow reflects this precision: Slack → question interpretation → metric resolution → SQL generation → DWH query → formatted response.
Users can ask questions like "how many users were active during a given period," or "what is the trend of revenue for the last 3 months," and get a structured, reliable answer. The implications for speed and agility are clear: tasks that once required tickets, prioritization, and potentially days of waiting can now be resolved in seconds.
Why LLMs Alone Won't Cut It for Business Analytics
The temptation to simply connect a powerful LLM directly to a raw database schema is understandable. It seems like the path of least resistance. But OLX's experience underscores why this often leads to misleading or outright incorrect answers, which are far more dangerous than no answer at all when critical business decisions are on the line.
Here's the thing: business metrics aren't just database columns. A concept like "revenue," "ARPU" (Average Revenue Per User), or "leads" carries specific business logic, definitions, and often complex aggregations that aren't inherently understood by a database schema. Your raw tables might contain transaction amounts, but how you define and calculate "monthly recurring revenue" requires a semantic layer.
Moreover, natural language is inherently ambiguous. A question like "What happened with traffic in Romania?" requires the system to infer the specific metric (e.g., website visits, unique users), the exact geography, the relevant platform, and the time period. A raw LLM might make a plausible guess, but plausible isn't good enough for analytics. The system needs to be guided by a clear understanding of the business context.
And yet, perhaps the biggest challenge is that LLMs are engineered to sound correct and generate coherent text. In an analytics context, a polished but factually incorrect answer can be catastrophic. You're not looking for fluency; you're looking for truth. This is why Talk2Data was built as a semantic layer over *known* metrics, not as a free-form chat over raw data. It's about providing guardrails, not just a microphone.
The Foundation: Knowledge Engineering, Not Just Prompt Engineering
One of the most profound takeaways from OLX's journey is that the success of AI-driven analytics hinges less on clever prompt engineering and more on fundamental data quality and governance. If your company struggles with inconsistent metric definitions, relies on different "sources of truth" across teams, or has conflicting data interpretations, an AI interface will only make these issues glaringly obvious.
To get Talk2Data to produce reliable answers, significant groundwork was essential. Teams had to:
- Rigorously formalize metric definitions.
- Align on definitive sources of truth for key data points.
- Define valid dimensions and establish a clear entity vocabulary.
This isn't just about cleaning data; it's about *knowledge engineering*. It involves standardizing analytics practices across the organization, making sure everyone speaks the same data language. The AI agent, in a way, served as a catalyst, forcing the organization to confront and resolve its long-standing data inconsistencies.
Establishing Trust: A Multi-Tiered Evaluation Process
Because accurate answers are non-negotiable for decision-making, OLX implemented a comprehensive evaluation process. This wasn't a casual check; it was a multi-tiered validation system:
- System-level validation: Standard unit and integration tests for the underlying components.
- Experimentation with predefined datasets: A critical step involving a dataset of 15-30 representative questions, each with its expected SQL query. This allows for repeatable evaluation of changes, aiming for a 95%+ pass rate by comparing agent responses to known correct SQL execution results.
- Live monitoring: Ongoing evaluation of real user queries in production to ensure consistent accuracy and proper usage.
This systematic approach ensures that the "sounding correct" problem inherent in LLMs is mitigated by objective, empirical validation. It builds trust in the system, which is paramount for user adoption.
The Human Element: Training Users to Ask Better Questions
Even with a sophisticated AI agent, the human element remains crucial. While natural language significantly lowers the barrier to data access, it doesn't eliminate the need for precision. OLX found that users got better results when they:
- Used exact metric names rather than vague terms.
- Specified dates clearly (e.g., "last 3 months" instead of "recently").
- Included platform or geography details when relevant.
- Split complex questions into simpler, more manageable queries.
This highlights the importance of user onboarding and education. Providing demos and clear documentation with examples of effective and less effective questions is essential for fostering true self-service capabilities. The tool is only as good as the questions it receives.
Tangible Impact and Lessons for the Industry
The rollout of Talk2Data delivered two immediate, tangible benefits. First, it dramatically reduced the volume of repetitive ad-hoc requests hitting the analytics team, freeing up analysts for more strategic, complex work. Second, business stakeholders gained significant time back, moving from waiting days for data to getting answers in seconds. An interesting side effect was its unexpected value to finance teams, who often face similar data access challenges but with limited dedicated analytics support.

What OLX's experience teaches us is that the path to effective AI-driven analytics self-service isn't about throwing an LLM at your data warehouse. It's about a disciplined, multi-faceted approach. If you're contemplating a similar project, you'll want to prioritize these:
- Start with clearly defined business use cases and metrics. If your organization lacks alignment on these, AI will only exacerbate existing chaos.
- Implement a robust, multi-level evaluation process. Trust in the data is paramount, and that demands rigorous testing and monitoring.
- Invest heavily in user onboarding and training. Empowering users means teaching them how to effectively interact with the system, not just handing them a new tool.
Ultimately, the success of AI in analytics comes down to the quality and structure of the underlying data and the intentionality of the system design. It's a reminder that while AI offers incredible potential, it functions best when integrated into well-governed, thoughtfully engineered systems. This isn't just a technical challenge; it's a strategic imperative for any data-driven organization.