The Silent Failure of Internal Developer Platforms: Why Billions Are Being Bypassed
There's a paradox brewing in enterprise software engineering, and it's costing organizations millions while slowing down their best developers. Internal Developer Platforms (IDPs) are undeniably the industry's darling, attracting billions in investment and headcount. Gartner projects a staggering 80% of large software engineering organizations will boast a dedicated platform team by the close of 2026, a sharp increase from about 45% just three years prior. This isn't just a trend; it's a fundamental shift in how companies aim to scale their software delivery.
And yet, a quietly devastating statistic recently surfaced from a Medium post that’s been making the rounds: a major engineering organization poured $4.2 million over 18 months into an IDP initiative, complete with a Backstage portal, Kubernetes golden paths, and all the bells and whistles. The outcome? A developer satisfaction survey revealed that 64% of engineers were still sidestepping the entire platform, opting instead to deploy with a raw kubectl run command. Let that sink in. Sixty-four percent. After over four million dollars and a year and a half of effort.
This isn't an isolated incident. My read, after years spent architecting cloud platforms and building internal tooling, is that this represents a widespread pattern. The problem isn't typically the technology itself. It’s a profound disconnect in how these platforms are conceived and delivered.
What Platform Engineering Actually Promises
To be clear, platform engineering isn't simply DevOps re-branded. It represents a very specific organizational model built on a singular, powerful idea: treating internal infrastructure as a product, with your development teams as its primary customers. What does that entail?
- A self-service portal, frequently Backstage, allowing engineers to provision environments, launch services, and access templates without the friction of opening a ticket.
- "Golden paths" – these are the opinionated, pre-approved patterns designed for how services should be built, deployed, and operated consistently.
- Automated guardrails for compliance, security scanning, and cost management, embedded right from the start.
- A dedicated platform team that commits to owning and nurturing this capability as a long-lived product.
The promise here is compelling. Mature IDPs regularly report dramatic cuts in provisioning lead times, stronger security postures, and a significantly lighter cognitive load on individual engineers. The 2025 DORA Report highlighted that 90% of organizations have now adopted at least one internal platform, and critically, there's a direct link between high-quality internal platforms and an organization's capacity to unlock real value from AI. Platform engineering is, in theory, the ultimate mechanism for consistent, high-quality delivery at scale.
So, given all that, why the bypass? Why the silent failures?
The Core Miscalculations Driving IDP Adoption Failures
The failures often boil down to three fundamental miscalculations, largely stemming from a missing product mindset.
The Platform Was Built for the Builders, Not the Users
Here’s an uncomfortable truth: most IDP implementations are constructed by infrastructure aficionados for developers who'd frankly rather not engage with infrastructure at all. Platform engineers inherently find the intricacies of Kubernetes, Terraform, and service mesh configurations deeply interesting. That’s why they do the job.
But the developers consuming the platform have a different mission: shipping features. They don't care about the elegance of your Helm chart templating; they care whether they can go from an idea to a running service without spending three hours deciphering internal documentation. A "golden path" that isn't the path of least resistance will inevitably be abandoned. Every single time.
We see this constantly: a platform team crafts a technically sound service template, enforcing all the right security policies, observability hooks, and resource limits. Yet, to get a new service running end-to-end, it demands seven configuration steps and two approvals, taking 45 minutes. The engineer needing a service now will simply run kubectl run, getting it done in four minutes. Your platform hasn't failed due to technical inferiority; it's failed because it prioritized correctness over developer experience.
Cost Visibility Became an Afterthought
This is a recurring problem across the industry. Platform teams pour resources into deployment pipelines, secret management, and service catalogs. Spend visibility, however, typically gets tacked on at the end or offloaded to a FinOps team that churns out monthly reports few engineers actually read.
The outcome is entirely predictable: engineers provision environments without any real-time feedback on their associated costs. A perfectly innocuous-looking ephemeral test environment, perhaps for a load test, gets forgotten and quietly accumulates significant monthly spend. Multiply that across dozens of teams, and you’re looking at a cost problem that no amount of Kubernetes right-sizing will magically fix. Cloud and AI costs today are neither predictable nor linear. Ephemeral environments, GPU-intensive workloads, managed services, and AI inference can drastically shift spend in days, not months. Cost guardrails need to be woven into the platform's fabric, not merely positioned adjacent to it. The platforms that surface cost impact at the point of provisioning—e.g., "this environment will cost approximately £180/month, confirm?"—alter engineer behavior in a way that retrospective reporting never will. Feedback loops only work when they are immediate and contextual.
The Platform Fails to Integrate With How Engineers Actually Work
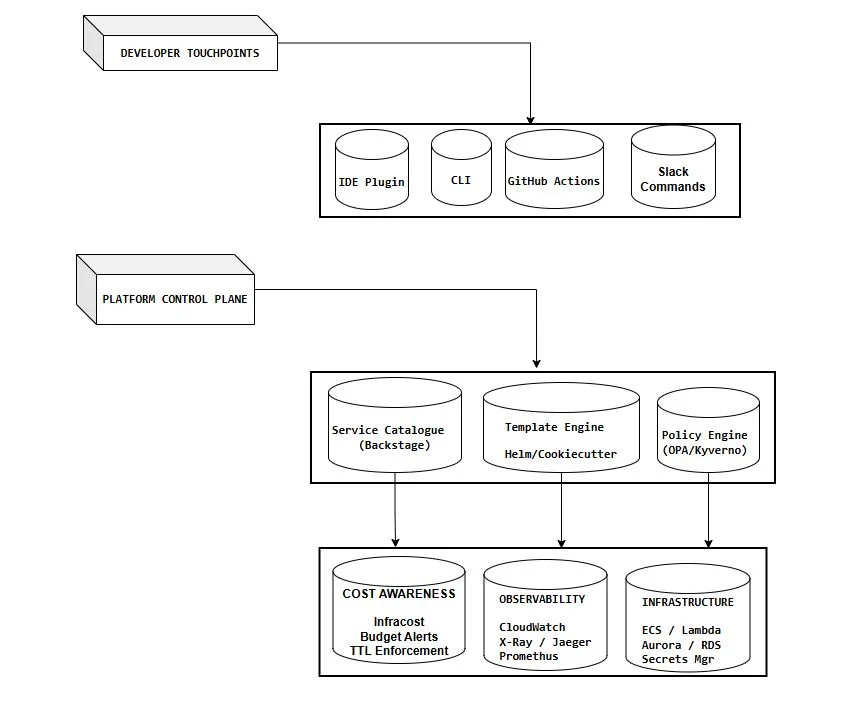
Most IDPs are designed around a portal interaction model: an engineer logs into Backstage, clicks through a wizard, provisions a resource. It's clean, auditable, and governed. But most engineers don't operate that way. Their workflow lives in their IDE, their terminal, Slack, and GitHub. They want to type a command or trigger an action from their current context, not switch to a separate web interface.
The 64% of engineers bypassing the platform for a raw kubectl run command aren't being lazy. They're rationally optimizing for the quickest path to accomplish their actual job. If your platform doesn't meet them where they are, they will inevitably route around it. The platforms that achieve the highest adoption are those that are invisible during low-friction moments and prominently visible during high-risk moments. You don't necessarily need a portal for deploying a staging environment; a CLI command, a GitHub Actions workflow, or a Slack slash command will often suffice. But you absolutely need a visible, enforced gate when someone attempts to deploy untested code to production.
What Actually Works: Engineering for Developer Experience
After observing numerous platform implementations, a clear pattern emerges among the successful ones. It centers on a relentless focus on the developer experience.
Developer Experience as a First-Class Metric
The most effective platform teams measure adoption much like a product team tracks user retention. They don't just ask, "is the platform being used?" They go deeper: "At which points in the workflow do engineers abandon it, and why?" They hold office hours, embed platform engineers into product squads to observe friction firsthand, and treat a low Net Promoter Score (NPS) from a developer team as a critical bug, not merely a culture problem. The 2024 DORA Report underscored this, confirming that internal developer platforms improve individual productivity, team performance, and overall organizational performance, but only when developer experience is treated as a core outcome.
The Golden Path Must Be Truly Golden
A "golden path" that necessitates three approvals and an internal ticket isn't a path; it's a bureaucracy with a friendly name. The best implementations I've seen genuinely collapse provisioning time. A new service, correctly configured, fully observable, secure, and deployed to a non-production environment, should take under ten minutes, with no tickets or approvals for standard configurations. This requires the platform team to do the heavy lifting upfront: pre-negotiating security and compliance requirements with stakeholders and encoding them directly into the template. The approval happens once, at template design time, not every time an engineer uses it.
Cost Intelligence, Embedded Not Adjacent
This means integrating Infracost into every Terraform PR, providing environment cost estimates at provisioning time, and setting up automatic TTL warnings on ephemeral environments (e.g., "this environment has been running for 14 days with no activity, shut it down?"). It also means budget threshold alerts going directly to the team responsible, not just to a central FinOps function. This is the crucial shift from reactive cost reporting to proactive cost awareness. The aim isn't to stop engineers from spending money, it’s to make them spend it consciously.
This approach becomes even more vital in multi-cloud environments, which are rapidly becoming the norm. The Flexera 2026 State of the Cloud Report indicates that a majority of organizations now operate in hybrid or multi-cloud settings. This introduces a significant cost visibility gap; a platform team might have excellent visibility into AWS, reasonable insight into Azure, but limited real-time understanding of GCP, especially when teams adopt specialized AI platforms independently. Fragmented cost awareness leads to reactive cost governance. The IDPs that truly address this integrate multi-cloud cost intelligence directly into the developer workflow, allowing engineers to understand cost impact across providers at the point of decision. This moves cost management from a periodic finance exercise to an everyday engineering practice.
The Platform Grows in the Terminal, Not Just the Portal
The highest-adoption IDPs I've encountered all have a robust CLI story. A command like platform create service my-api --template=python-fastapi should simply work. platform env list --cost should clearly display running environments and their estimated monthly spend. And platform deploy --env=staging should be a single command that replicates the entire Backstage wizard experience without ever requiring an engineer to leave their terminal. This isn't about eliminating the portal; it's about making the platform usable in the contexts where engineers actually spend their time. Every developer touchpoint—be it the Backstage portal, a CLI command, a GitHub Actions workflow, or a Slack slash command—should communicate with the same control plane. This ensures that the same policy engine, cost checks, and observability hooks are applied consistently. The experience might differ, but the governance doesn't. That's how you achieve both high adoption and high compliance: not by forcing engineers into a single interface, but by making every interface they prefer equally safe and productive.
Practical Steps for Platform Teams
If you're currently building or trying to revive an IDP, here’s a sequence I'd recommend:
- Measure adoption, not just deployment. Before adding any new features, instrument what's actually being used. Which golden paths have seen repeated use? Which platform-provisioned services are still running months later versus those created and then bypassed? This data will pinpoint the real friction.
- Drastically reduce provisioning time. Take your current end-to-end time for a new service from zero to deployed in a non-production environment and cut it in half. This is your single most important lever for adoption. Everything else is noise if the fundamental loop is slow.
- Build a strong CLI. Even a thin wrapper that calls your existing APIs. Get it into engineers' hands and observe how they use it. The commands they gravitate towards most naturally are the ones your portal experience needs to optimize around.
- Embed cost directly into the provisioning flow. Skip the link to a cost dashboard. Provide an inline estimate, at the precise moment of provisioning, that requires explicit acknowledgment. This single change will likely impact your cloud bill more than any rightsizing exercise.
- Establish a regular platform NPS cadence. Quarterly is the bare minimum; monthly is significantly better. Treat any score below 7 from a developer team as an incident. Assign it, investigate it thoroughly, and fix it.
The Real Question for 2026: Product-Led vs. Infrastructure-Led
For engineering leaders looking ahead to 2026, the question isn't whether internal platforms will exist. Gartner's forecast makes their widespread presence inevitable. The question is whether these platforms will be intentional or accidental. The difference manifests directly in adoption rates, resilience, and the ability to evolve without constant, costly rework.
But I'd push that framing even further: the core question isn't just intentional versus accidental. It's about being product-led versus infrastructure-led.
Platforms designed by those who primarily love infrastructure, and therefore optimized for technical correctness above all else, will continue to see bypass rates north of 60%. Conversely, platforms built by teams that genuinely understand their users—developers trying to ship fast—and are optimized for experience first (while still rigorously enforcing governance) will encounter the opposite problem: engineers will actively seek to use them, even for tasks that might not strictly require it. That's the ultimate goal. Build a platform so genuinely useful and well-designed that bypassing it feels like leaving performance, security, or efficiency on the table.
Four million dollars and 18 months for a platform 64% of engineers actively avoid. I share that statistic not to mock the team that built it, but because it could easily be any of us. The underlying infrastructure was likely excellent. The golden paths were probably technically sound. The Backstage portal might have been beautifully designed. And yet, none of it mattered because the fundamental product thinking wasn't there from the very beginning. Platform engineering is one of the most exciting and impactful disciplines in our field right now. It's also the one where the gap between what we typically measure (did we deploy a platform?) and what we absolutely *should* measure (are engineers choosing to use it and finding it valuable?) is widest. Close that gap. Everything else follows.